【分享】影刀使用xpath捕获指定的元素
xpath捕获元素比较精准,前面也介绍了xpath的用法
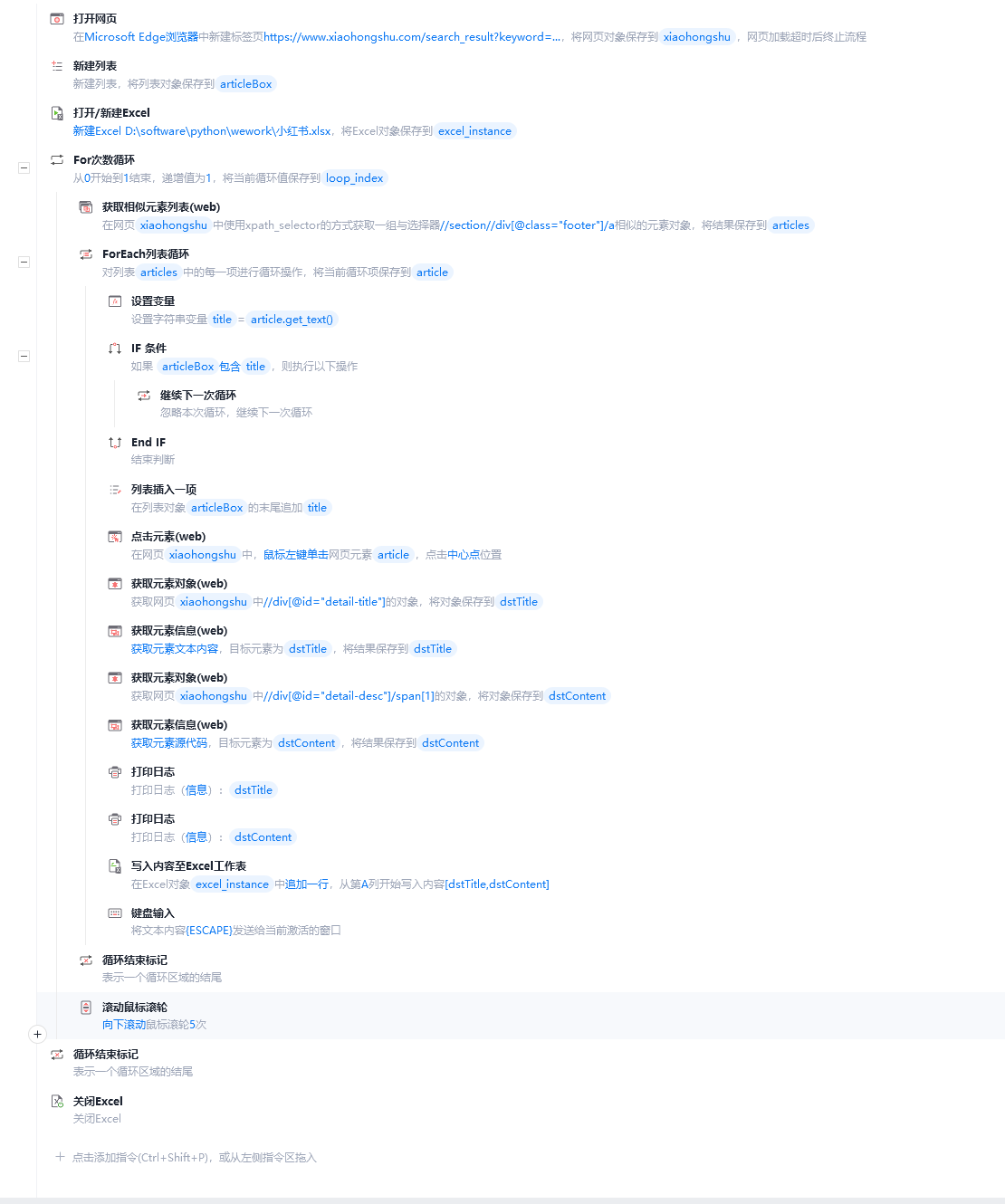
现在捕获社区里帖子详情页的标题
//*[@class='discuss_detail_header___3LhnQ']/h1
找到class是discuss_detail_header___3LhnQ的子元素h1

获取文章内容
//*[@id='w-e-textarea-1']
找到id是w-e-textarea-1的元素
获取元素的源代码,就可以获取到html内容了